
1、LSTM的发展历程
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络(Recurrent Neural Network,RNN),由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出。LSTM的出现是为了解决传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题。
在传统的RNN中,信息通过时间步逐步传递,但随着时间步的增加,RNN在处理长序列时往往难以捕捉到早期的信息。这是因为RNN的梯度在反向传播过程中会随着时间步的增加而指数级衰减或增长,导致模型无法有效地学习长期依赖关系。LSTM通过引入一种特殊的记忆单元和门控机制,成功地解决了这一问题,使得网络能够更好地捕捉长序列中的依赖关系。
2、LSTM如何克服RNN的梯度爆炸问题
2.1 RNN的梯度爆炸问题
在传统的RNN中,梯度是通过时间反向传播(Backpropagation Through Time,BPTT)计算的。在BPTT过程中,梯度会随着时间步的增加而不断累积。如果梯度值大于1,经过多次累积后,梯度会变得非常大,导致权重更新过度,这种现象称为梯度爆炸。梯度爆炸会导致模型训练不稳定,甚至无法收敛。
2.2 LSTM如何解决梯度爆炸问题
LSTM通过引入门控机制和记忆单元,有效地控制了信息的流动,从而避免了梯度爆炸问题。具体来说,LSTM通过以下几个关键组件来实现这一目标:
- 记忆单元(Cell State):LSTM的核心是记忆单元,它能够在长时间内保持信息不变。记忆单元通过线性操作传递信息,避免了梯度在传递过程中的指数级增长或衰减。
- 门控机制:LSTM引入了三种门控机制:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。这些门控机制通过Sigmoid函数来控制信息的流动,确保只有重要的信息被保留,不重要的信息被遗忘。
- 遗忘门:决定哪些信息应该从记忆单元中丢弃。通过Sigmoid函数,遗忘门输出一个介于0和1之间的值,表示保留或遗忘的程度。
- 输入门:决定哪些新信息应该被添加到记忆单元中。输入门通过Sigmoid函数和Tanh函数结合,控制新信息的流入。
- 输出门:决定哪些信息应该从记忆单元中输出。输出门通过Sigmoid函数和Tanh函数结合,控制信息的输出。
通过这些门控机制,LSTM能够有效地控制信息的流动,避免了梯度在反向传播过程中的爆炸问题。此外,LSTM的记忆单元通过线性操作传递信息,避免了梯度在传递过程中的指数级变化,从而使得LSTM能够更好地处理长序列数据。
3、LSTM的工作原理
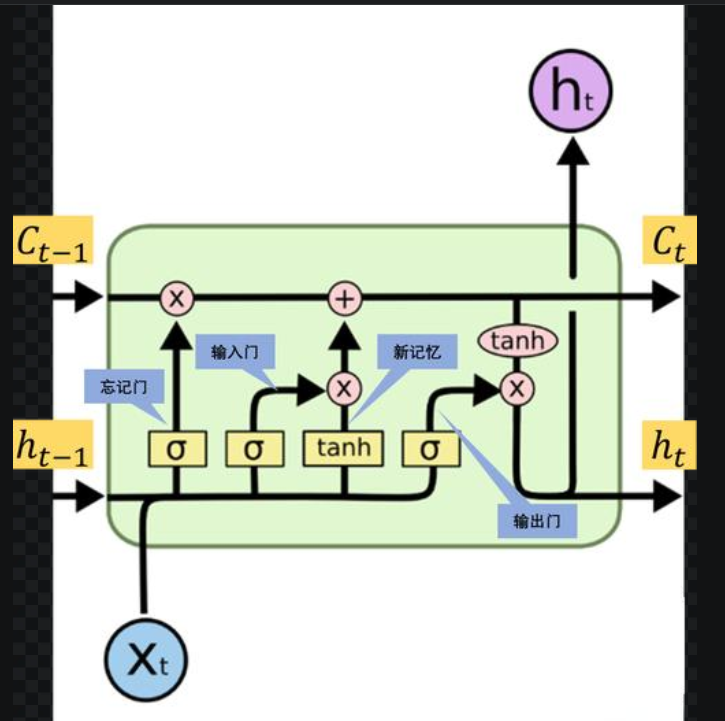
3.1 记忆单元和门控机制
LSTM的核心是记忆单元(Cell State),它能够在长时间内保持信息不变。记忆单元通过线性操作传递信息,避免了梯度在传递过程中的指数级变化。LSTM通过三种门控机制来控制信息的流动:
- 遗忘门(Forget Gate):遗忘门决定哪些信息应该从记忆单元中丢弃。遗忘门的输出是一个介于0和1之间的值,表示保留或遗忘的程度。遗忘门的计算公式为:

- 输入门(Input Gate):输入门决定哪些新信息应该被添加到记忆单元中。输入门的输出也是一个介于0和1之间的值,表示新信息的流入程度。输入门的计算公式为:
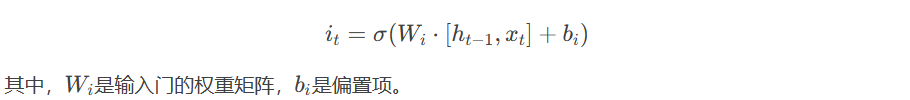
- 候选记忆单元(Candidate Cell State):候选记忆单元表示当前时间步的新信息。它通过Tanh函数计算得到:

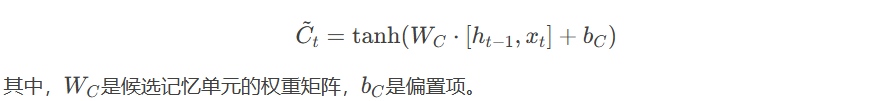
- 更新记忆单元(Cell State Update):记忆单元的更新通过遗忘门和输入门的输出进行控制。更新公式为:
- 输出门(Output Gate):输出门决定哪些信息应该从记忆单元中输出。输出门的输出也是一个介于0和1之间的值,表示输出的程度。输出门的计算公式为:
- 隐藏状态(Hidden State):隐藏状态是LSTM的输出,它通过输出门和记忆单元的计算得到:
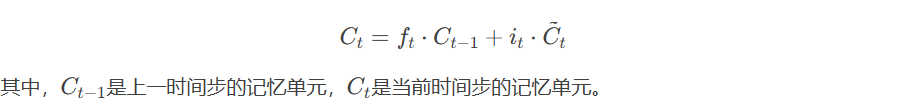
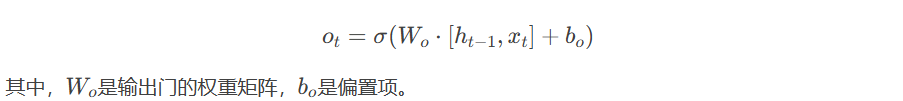
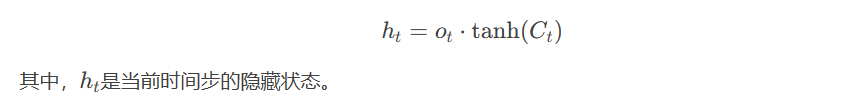
3.2 LSTM的前向传播
LSTM的前向传播过程可以总结为以下几个步骤:
通过这些步骤,LSTM能够在每个时间步有效地处理输入数据,并保留重要的信息。
4、LSTM的应用举例及优势说明
4.1 LSTM的应用举例
LSTM由于其强大的序列建模能力,被广泛应用于各种领域,包括但不限于:
- 自然语言处理(NLP):LSTM在机器翻译、文本生成、情感分析等任务中表现出色。例如,在机器翻译中,LSTM能够捕捉到句子中的长期依赖关系,从而生成更准确的翻译结果。
- 语音识别:LSTM被用于语音识别任务中,能够有效地处理音频信号中的时间序列数据,识别出语音中的单词和句子。
- 时间序列预测:LSTM在股票价格预测、天气预测等时间序列预测任务中表现出色。它能够捕捉到时间序列数据中的长期趋势和周期性变化。
- 视频分析:LSTM被用于视频分类、动作识别等任务中,能够处理视频帧序列中的时间信息,识别出视频中的动作和事件。
4.2 LSTM的优势
LSTM相比传统的RNN具有以下几个优势:
- 长期依赖建模:LSTM通过记忆单元和门控机制,能够有效地捕捉到序列数据中的长期依赖关系,解决了传统RNN在处理长序列时的梯度消失和梯度爆炸问题。
- 灵活性:LSTM的门控机制使得它能够灵活地控制信息的流动,保留重要的信息,丢弃不重要的信息,从而提高了模型的表达能力。
- 广泛应用:LSTM在自然语言处理、语音识别、时间序列预测等领域都有广泛的应用,且表现出色。
5、LSTM的升级版本
随着深度学习的发展,LSTM的变体和改进版本不断涌现,这些变体在保持LSTM核心优势的同时,进一步优化了模型结构、计算效率和应用范围。以下是几种常见的LSTM升级版本及其特点、优缺点和应用场景。
5.1 门控循环单元(GRU, Gated Recurrent Unit)
5.1.1 GRU的由来
门控循环单元(GRU)是由Cho等人于2014年提出的一种LSTM变体。GRU的设计目标是简化LSTM的结构,同时保留其处理长序列数据的能力。GRU通过减少门控机制的数量,降低了模型的复杂度,从而提高了计算效率。
5.1.2 GRU的结构
GRU将LSTM中的输入门和遗忘门合并为一个“更新门”(Update Gate),并去除了输出门,引入了“重置门”(Reset Gate)。其核心结构如下:
- 更新门(Update Gate):控制当前状态中有多少信息来自前一时刻的隐藏状态,有多少信息来自当前输入。
- 重置门(Reset Gate):决定前一时刻的隐藏状态对当前候选状态的影响程度。
- 候选隐藏状态(Candidate Hidden State):基于重置门和当前输入计算候选状态。
- 隐藏状态更新:通过更新门结合前一时刻的隐藏状态和候选隐藏状态。
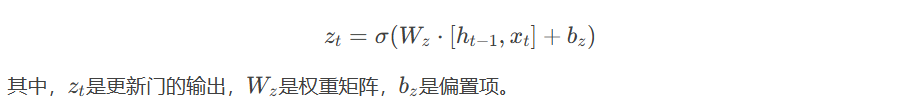
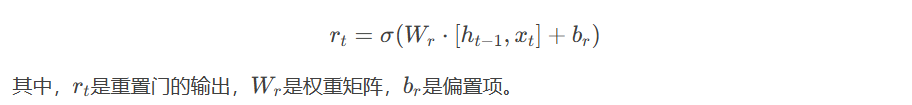
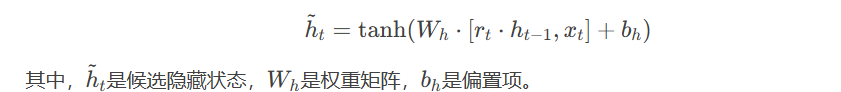
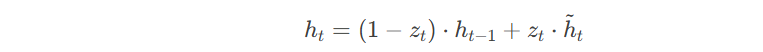
5.1.3 GRU的优缺点
- 优点:
- 计算效率高:GRU的结构比LSTM更简单,参数更少,训练速度更快。
- 性能接近LSTM:在许多任务中,GRU的表现与LSTM相当,甚至更好。
- 适合短序列数据:对于较短的序列数据,GRU的表现通常优于LSTM。
- 缺点:
- 长期依赖建模能力稍弱:由于结构简化,GRU在处理极长序列时的表现可能略逊于LSTM。
- 灵活性较低:GRU的门控机制较少,对信息的控制能力不如LSTM精细。
5.1.4 GRU的应用
GRU广泛应用于以下领域:
- 自然语言处理:如文本分类、机器翻译、语音识别等。
- 时间序列预测:如股票价格预测、气象预测等。
- 推荐系统:基于用户行为序列的个性化推荐
5.2 双向LSTM(BiLSTM, Bidirectional LSTM)
5.2.1 双向LSTM的由来
双向LSTM是由Schuster和Paliwal于1997年提出的一种LSTM变体。其核心思想是通过同时考虑序列的前向和后向信息,增强模型对上下文的理解能力
5.2.2 双向LSTM的结构
双向LSTM由两个独立的LSTM组成:
- 前向LSTM:从序列的起点到终点处理数据,捕捉前向依赖关系。
- 后向LSTM:从序列的终点到起点处理数据,捕捉后向依赖关系。
最终的输出是前向LSTM和后向LSTM的隐藏状态的拼接: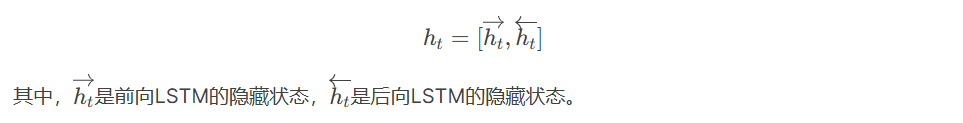
5.2.3 双向LSTM的优缺点
- 优点:
- 上下文信息更丰富:双向LSTM能够同时捕捉序列的前向和后向依赖关系,适用于需要全局上下文信息的任务。
- 性能提升显著:在自然语言处理等任务中,双向LSTM的表现通常优于单向LSTM。
- 缺点:
- 计算复杂度高:双向LSTM需要同时运行两个LSTM,计算成本较高。
- 不适合在线任务:由于需要同时访问序列的过去和未来信息,双向LSTM无法应用于实时流数据任务。
5.2.4 双向LSTM的应用
双向LSTM广泛应用于以下领域:
- 自然语言处理:如命名实体识别(NER)、语义角色标注(SRL)、情感分析等。
- 语音识别:通过捕捉语音信号的前后文信息,提高识别准确率。
- 生物信息学:如蛋白质结构预测、基因序列分析等。
5.3 深度LSTM(Deep LSTM)
5.3.1 深度LSTM的由来
深度LSTM是通过堆叠多个LSTM层来构建的深层网络结构。其设计灵感来源于深度神经网络(DNN),通过增加网络深度来提高模型的表达能力。
5.3.2 深度LSTM的结构
深度LSTM由多个LSTM层堆叠而成,每一层的输出作为下一层的输入。其结构如下: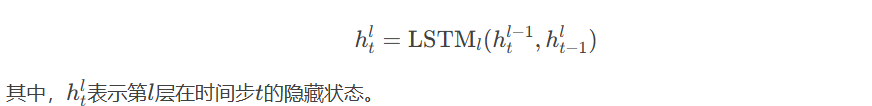
5.3.3 深度LSTM的优缺点
- 优点:
- 表达能力更强:通过增加网络深度,深度LSTM能够捕捉更复杂的序列模式。
- 适合复杂任务:在处理高维数据或复杂序列任务时,深度LSTM的表现通常优于单层LSTM。
- 缺点:
- 训练难度大:深层网络容易产生梯度消失或梯度爆炸问题,训练过程需要更精细的调参。
- 计算成本高:深层网络的参数更多,计算复杂度更高。
5.3.4 深度LSTM的应用
深度LSTM广泛应用于以下领域:
- 机器翻译:通过深层网络捕捉语言之间的复杂映射关系。
- 语音合成:生成高质量的语音信号。
- 视频分析:处理视频帧序列中的复杂时空信息。
5.4 其他LSTM变体
5.4.1 窥视孔LSTM(Peephole LSTM)
窥视孔LSTM在LSTM的门控机制中引入了记忆单元的连接,使得门控机制能够直接访问记忆单元的信息。这种设计增强了门控机制的控制能力,但增加了模型的复杂度。
5.4.2 卷积LSTM(ConvLSTM)
卷积LSTM将卷积操作引入LSTM中,适用于处理具有空间结构的序列数据(如图像序列、视频帧)。其核心思想是用卷积操作替代全连接操作,从而捕捉空间依赖性。
5.4.3 注意力LSTM(Attention LSTM)
注意力LSTM结合了注意力机制和LSTM,能够动态地关注序列中的重要部分。这种设计在机器翻译、文本摘要等任务中表现出色
总结
LSTM及其变体(如GRU、双向LSTM、深度LSTM等)在序列建模任务中表现出色,广泛应用于自然语言处理、语音识别、时间序列预测等领域。每种变体都有其独特的优势和适用场景:
- GRU:计算效率高,适合短序列任务。
- 双向LSTM:上下文信息丰富,适合需要全局信息的任务。
- 深度LSTM:表达能力更强,适合复杂任务。
未来,随着深度学习技术的不断发展,LSTM及其变体将继续优化,并在更多领域发挥重要作用。同时,结合注意力机制、自监督学习等新技术,LSTM的性能和应用范围将进一步扩展。
6、LSTM的未来发展
尽管LSTM在许多任务中表现出色,但它仍然面临一些挑战和限制。未来的发展方向可能包括:
- 更高效的模型:LSTM的计算复杂度较高,尤其是在处理长序列数据时。未来的研究可能会集中在开发更高效的LSTM变体,以减少计算成本。
- 结合注意力机制:注意力机制(Attention Mechanism)在序列建模任务中表现出色。未来的研究可能会探索如何将LSTM与注意力机制结合,以进一步提高模型的性能。
- 多模态学习:未来的研究可能会探索如何将LSTM应用于多模态数据(如文本、图像、音频等)的学习任务中,以处理更复杂的现实世界问题。
- 自监督学习:自监督学习是一种无需大量标注数据的学习方法。未来的研究可能会探索如何将LSTM应用于自监督学习任务中,以减少对标注数据的依赖。
总之,LSTM作为一种强大的序列建模工具,在未来仍然具有广阔的发展前景。随着深度学习技术的不断进步,LSTM及其变体将继续在各个领域发挥重要作用。

👍
好人一胎8个儿子
好资料
谢谢分享